
آخرین مطالب
امکانات وب


در این پست می خواهیم نگاهی به روشی برای مقایسه دو توزیع احتمال به نام واگرایی Kullback-Leibler (که اغلب فقط با واگرایی KL کوتاه می شوند) نگاهی بیندازیم. اغلب در احتمال و آمار ، داده های مشاهده شده یا توزیع های پیچیده را با توزیع ساده تر و تقریبی جایگزین می کنیم. KL Divergence به ما کمک می کند تا هنگام انتخاب تقریب ، چه میزان اطلاعاتی را از دست می دهیم.
کرم های فضایی و واگرایی KL.
بیایید اکتشاف خود را با نگاه کردن به یک مشکل شروع کنیم. فرض کنید که ما دانشمندان فضایی هستیم که از یک سیاره دور و جدید بازدید می کنیم و گونه ای از کرم های گزنده را که دوست داریم مطالعه کنیم کشف کرده ایم. ما دریافتیم که این کرم ها دارای 10 دندان هستند ، اما به دلیل همه چیز دور ، بسیاری از آنها به دندانهای گمشده می رسند. پس از جمع آوری نمونه های بسیاری ، ما به این توزیع احتمال تجربی تعداد دندان ها در هر کرم رسیده ایم:
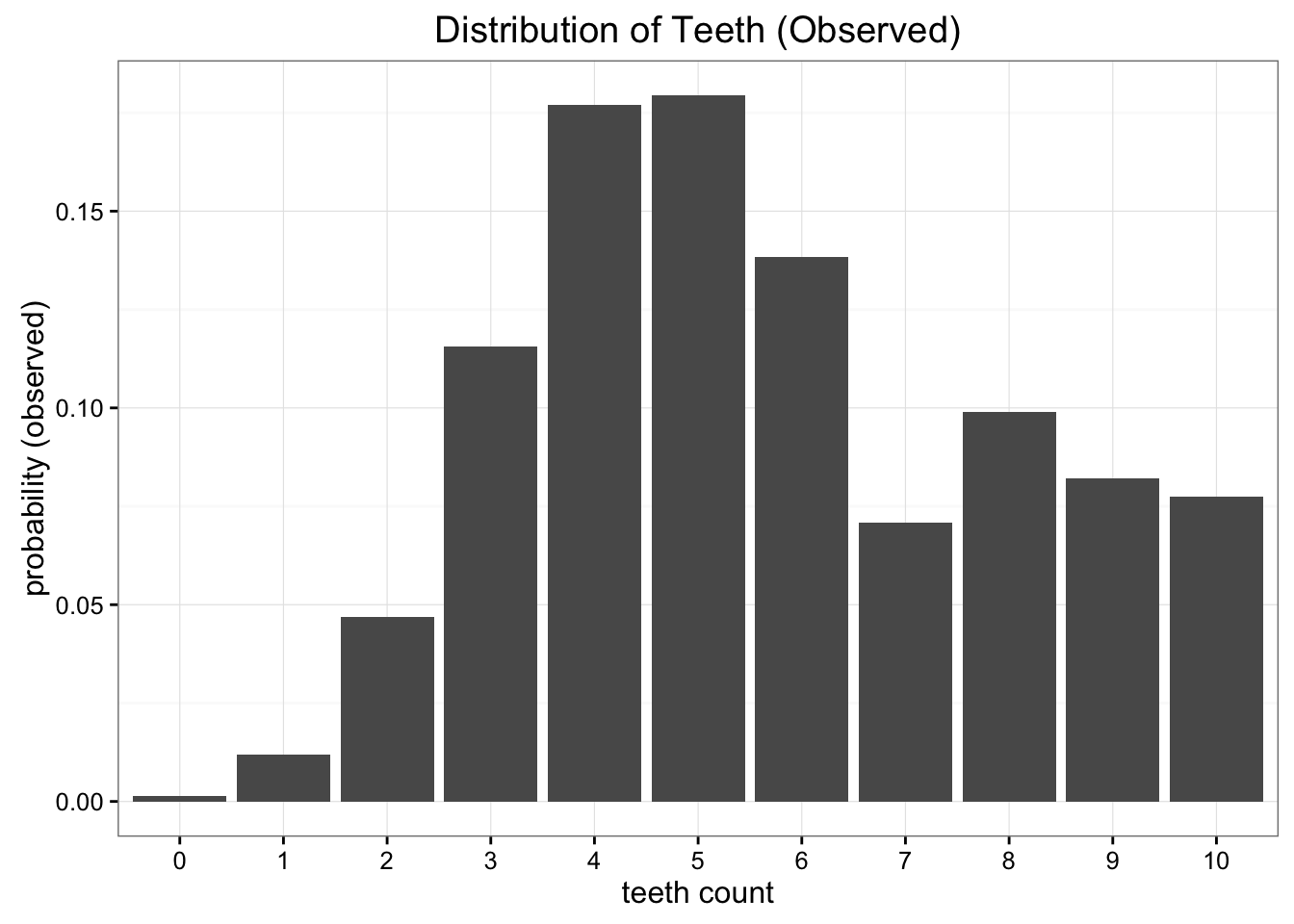
توزیع احتمال تجربی داده های جمع آوری شده
در حالی که این داده ها عالی است ، ما کمی مشکل داریم. ما از زمین دور هستیم و ارسال داده ها به خانه گران است. کاری که ما می خواهیم انجام دهیم این است که فقط یک یا دو پارامتر این داده ها را به یک مدل ساده کاهش دهیم. یکی از گزینه ها نشان دادن توزیع دندان در کرم ها به عنوان توزیع یکنواخت است. ما می دانیم که 11 مقدار ممکن وجود دارد و فقط می توانیم احتمال یکنواخت ( frac ) را به هر یک از این امکانات اختصاص دهیم.
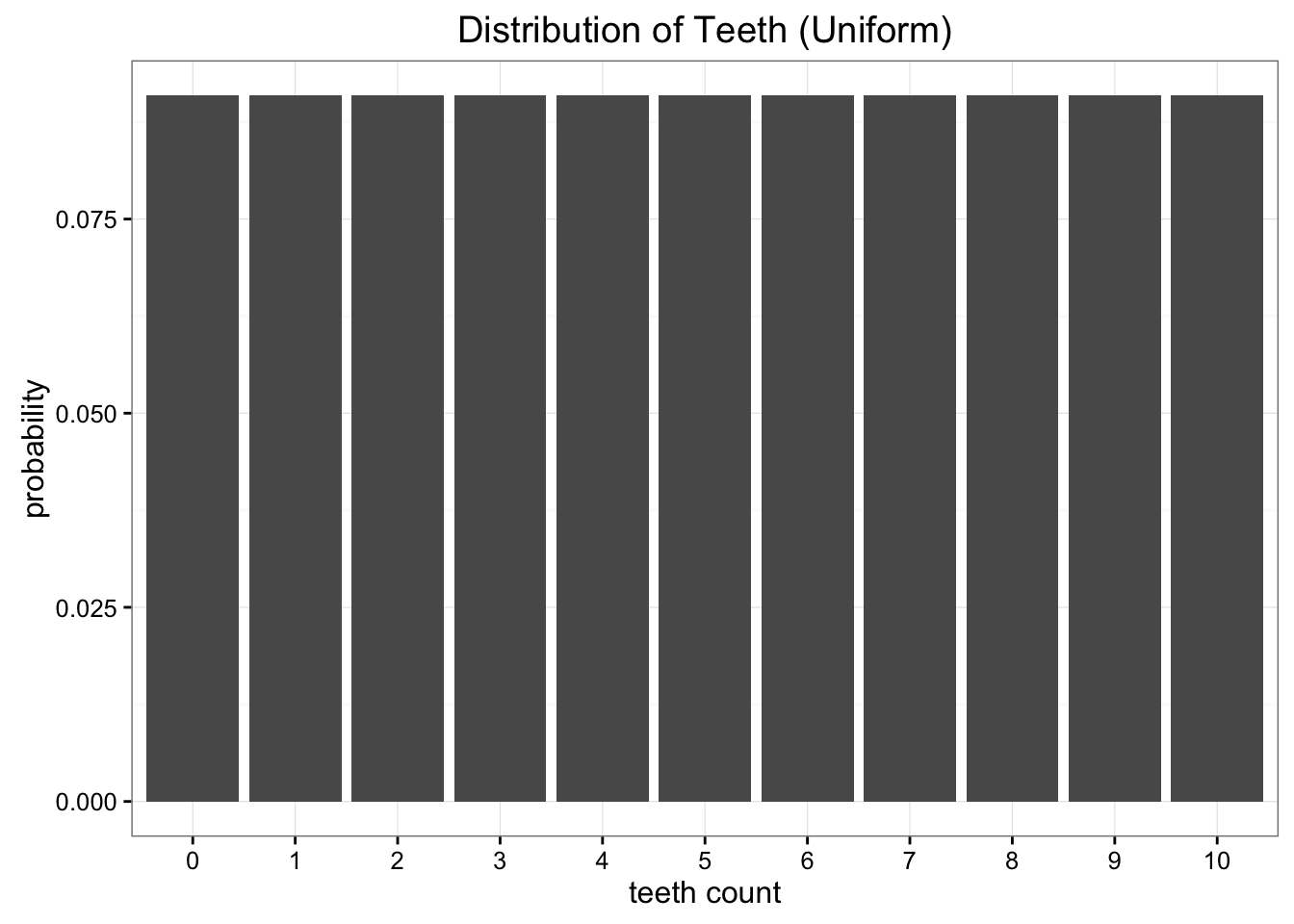
تقریب یکنواخت ما هرگونه تفاوت در داده های ما را از بین می برد
واضح است که داده های ما به طور یکنواخت توزیع نمی شوند ، اما مانند هر توزیع مشترکی که می دانیم نیز به نظر نمی رسد. گزینه دیگری که می توانیم امتحان کنیم این است که داده های خود را با استفاده از توزیع دوتایی مدل کنیم. در این حالت ، تمام کاری که ما باید انجام دهیم تخمین زده می شود که پارامتر احتمال توزیع دوتایی. ما می دانیم که اگر کارآزمایی (n ) داشته باشیم و یک احتمالی (p ) باشد ، انتظار فقط (e [x] = n cdot p ) است. در این حالت (n = 10 ) ، و انتظار فقط میانگین داده های ما است که ما می گوییم 5. 7 است ، بنابراین بهترین تخمین ما از P 0. 57 است. این به ما توزیع دوتایی می دهد که به نظر می رسد:
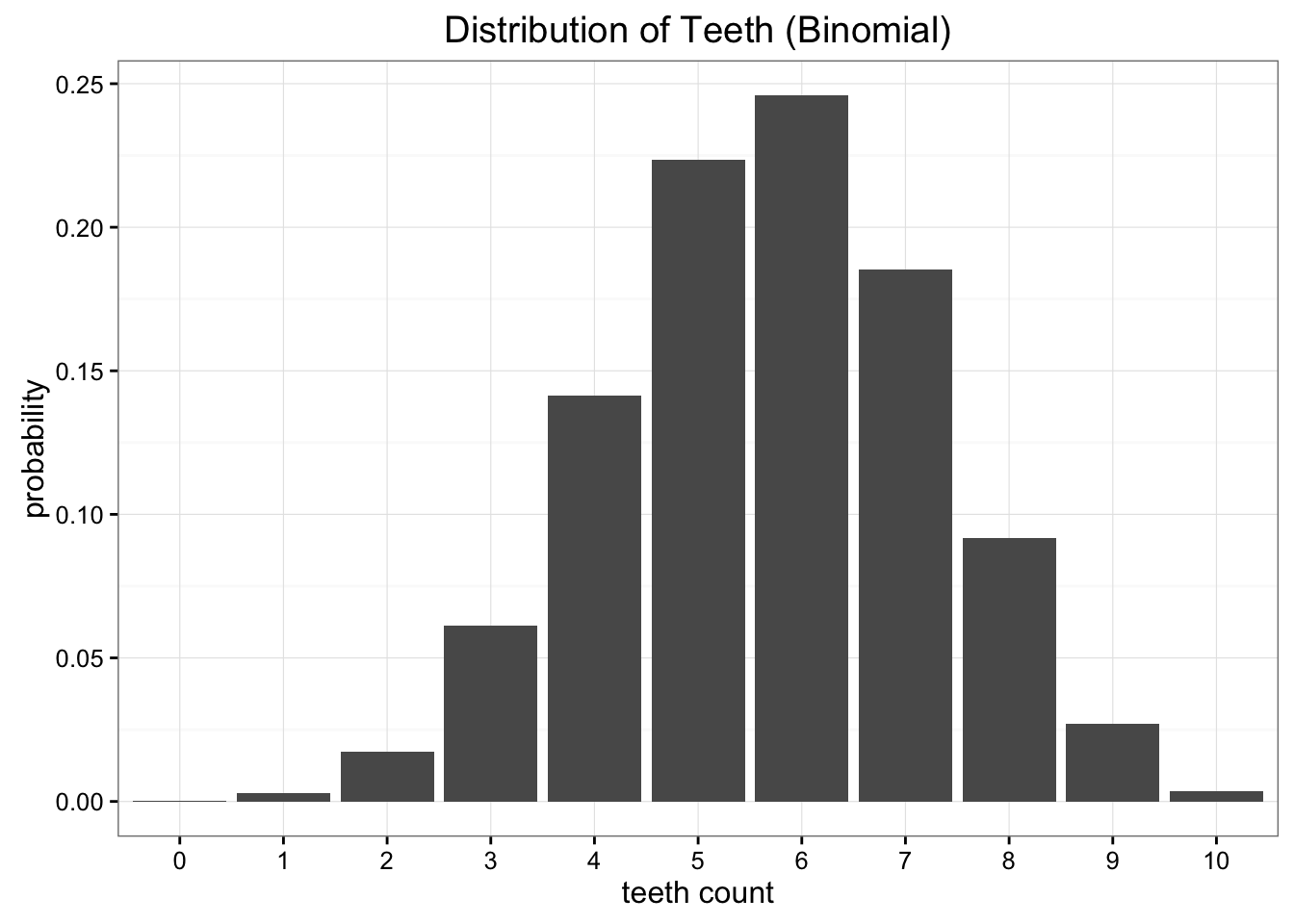
تقریب دوتایی ما ظرافت بیشتری دارد ، اما داده های ما را کاملاً مدل نمی کند
با مقایسه هر یک از مدل های ما با داده های اصلی ما می توانیم ببینیم که هیچ یک از مسابقات مناسب نیست ، اما کدام یک بهتر است؟
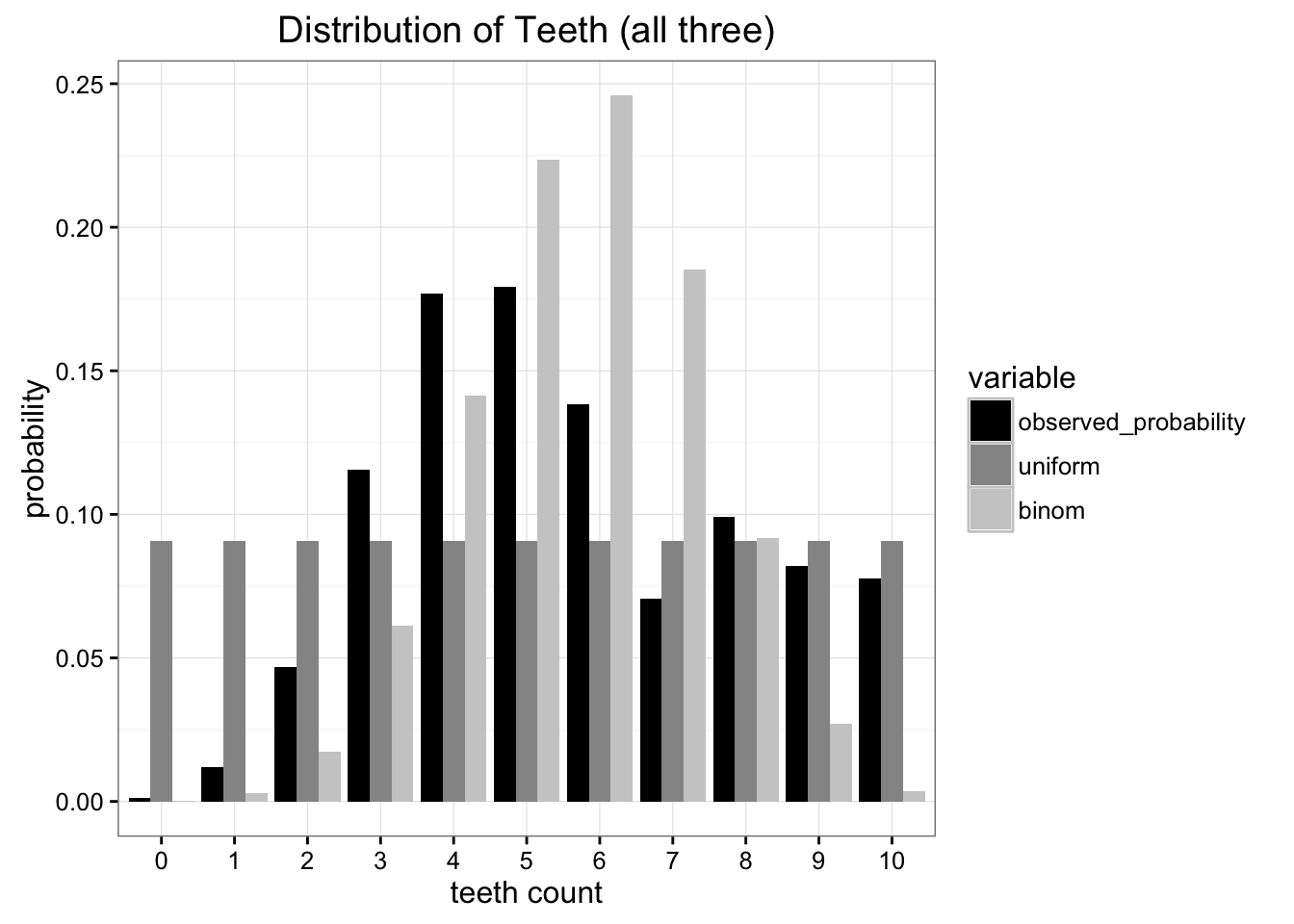
در مقایسه با داده های اصلی ، مشخص است که هر دو تقریب محدود هستند. چگونه می توانیم از کدام یک استفاده کنیم؟
معیارهای خطای موجود زیادی وجود دارد ، اما نگرانی اصلی ما به حداقل رساندن میزان اطلاعاتی است که باید ارسال کنیم. هر دوی این مدل ها مشکل ما را به دو پارامتر ، تعداد دندان ها و یک احتمال کاهش می دهند (اگرچه ما فقط برای توزیع یکنواخت به تعداد دندان ها نیاز داریم). بهترین آزمایش بهتر این است که بپرسیم کدام توزیع بیشترین اطلاعات را از منبع داده اصلی ما حفظ می کند. اینجاست که واگرایی Kullback-Leibler وارد می شود.
آنتروپی توزیع ما
KL Divergence منشأ خود را در تئوری اطلاعات دارد. هدف اصلی تئوری اطلاعات ، تعیین میزان اطلاعات در داده ها است. مهمترین متریک در تئوری اطلاعات ، آنتروپی نامیده می شود ، که به طور معمول به عنوان (H ) مشخص می شود. تعریف آنتروپی برای توزیع احتمال:
اگر از (log_2 ) برای محاسبه خود استفاده کنیم ، می توانیم آنتروپی را به عنوان "حداقل تعداد بیت ها ، ما را برای رمزگذاری اطلاعات خود" تفسیر کنیم. در این حالت ، اطلاعات با توجه به توزیع تجربی ما ، هر یک از مشاهده های دندان ها خواهد بود. با توجه به داده هایی که مشاهده کرده ایم ، توزیع احتمال ما دارای آنتروپی 3. 12 بیت است. تعداد بیت ها به ما می گوید که به طور متوسط تعداد بیت هایی که به آنها نیاز داریم ، به طور متوسط برای رمزگذاری تعداد دندان هایی که در یک مورد واحد مشاهده می کنیم ، به ما می گوید.
آنچه آنتروپی به ما نمی گوید ، طرح رمزگذاری بهینه برای کمک به ما در دستیابی به این فشرده سازی است. رمزگذاری بهینه اطلاعات موضوعی بسیار جالب است ، اما برای درک واگرایی KL لازم نیست. نکته اصلی آنتروپی این است که ، صرفاً دانستن پایین نظری در تعداد بیت های مورد نیاز ما ، راهی داریم که دقیقاً میزان اطلاعات در داده های ما را تعیین کنیم. اکنون که می توانیم این را کمیت کنیم ، می خواهیم وقتی توزیع مشاهده شده خود را برای تقریب پارامتری جایگزین می کنیم ، میزان اطلاعات را از دست بدهیم.
اندازه گیری اطلاعات از دست رفته با استفاده از واگرایی Kullback-Leibler
واگرایی Kullback-Leibler فقط یک اصلاح جزئی از فرمول ما برای آنتروپی است. ما به جای اینکه فقط توزیع احتمال خود را داشته باشیم (P ) توزیع تقریبی خود را اضافه می کنیم (q ). سپس ما به تفاوت مقادیر ورود به سیستم برای هر یک نگاه می کنیم:
در اصل ، آنچه ما با واگرایی KL به دنبال آن هستیم ، انتظار تفاوت ورود به سیستم بین احتمال داده در توزیع اصلی با توزیع تقریبی است. باز هم ، اگر از نظر (log_2 ) فکر کنیم می توانیم این موضوع را به عنوان "چند بیت اطلاعاتی که انتظار داریم از دست بدهیم" تعبیر کنیم. ما می توانیم فرمول خود را از نظر انتظار بازنویسی کنیم:
روش متداول تر برای دیدن واگرایی KL به شرح زیر است:
با واگرایی KL می توانیم دقیقاً چه مقدار اطلاعات را از دست می دهیم وقتی که یک توزیع را با دیگری تقریب می دهیم. بیایید به داده های خود برگردیم و ببینیم نتایج به نظر می رسد.
مقایسه توزیع های تقریبی ما
اکنون می توانیم پیش برویم و واگرایی KL را برای دو توزیع تقریبی خود محاسبه کنیم. برای توزیع یکنواخت که می یابیم:
و برای تقریب دوتایی ما:
همانطور که می بینیم اطلاعات از دست رفته با استفاده از تقریب دوتایی بیشتر از استفاده از تقریب یکنواخت است. اگر مجبور شویم یکی را انتخاب کنیم تا مشاهدات خود را نشان دهد ، بهتر است با تقریب یکنواخت بپیوندیم.
واگرایی فاصله ندارد
ممکن است فکر کردن در مورد واگرایی KL به عنوان یک متریک فاصله وسوسه انگیز باشد ، اما ما نمی توانیم از واگرایی KL برای اندازه گیری فاصله بین دو توزیع استفاده کنیم. دلیل این امر این است که واگرایی KL متقارن نیست. به عنوان مثال اگر ما از داده های مشاهده شده خود به عنوان روش تقریب توزیع دوتایی استفاده کنیم ، نتیجه بسیار متفاوتی کسب می کنیم:
$ $ d_ ( text || text) = 0. 330 $ $ به طور شهودی این امر معقول است زیرا در هر یک از این موارد ما شکل بسیار متفاوتی از تقریب انجام می دهیم.
بهینه سازی با استفاده از واگرایی KL
وقتی مقدار خود را برای توزیع دوتایی انتخاب کردیم ، با استفاده از مقدار مورد انتظار که با داده های ما مطابقت داشته باشد ، پارامتر خود را برای احتمال انتخاب کردیم. اما از آنجا که ما برای به حداقل رساندن از دست دادن اطلاعات بهینه سازی می کنیم ، ممکن است این بهترین راه انتخاب پارامتر نبود. ما می توانیم با نگاه به نحوه تغییر واگرایی KL ، با تغییر مقادیر خود برای این پارامتر ، کار خود را بررسی کنیم. در اینجا نمودار چگونگی تغییر این مقادیر با هم آورده شده است:
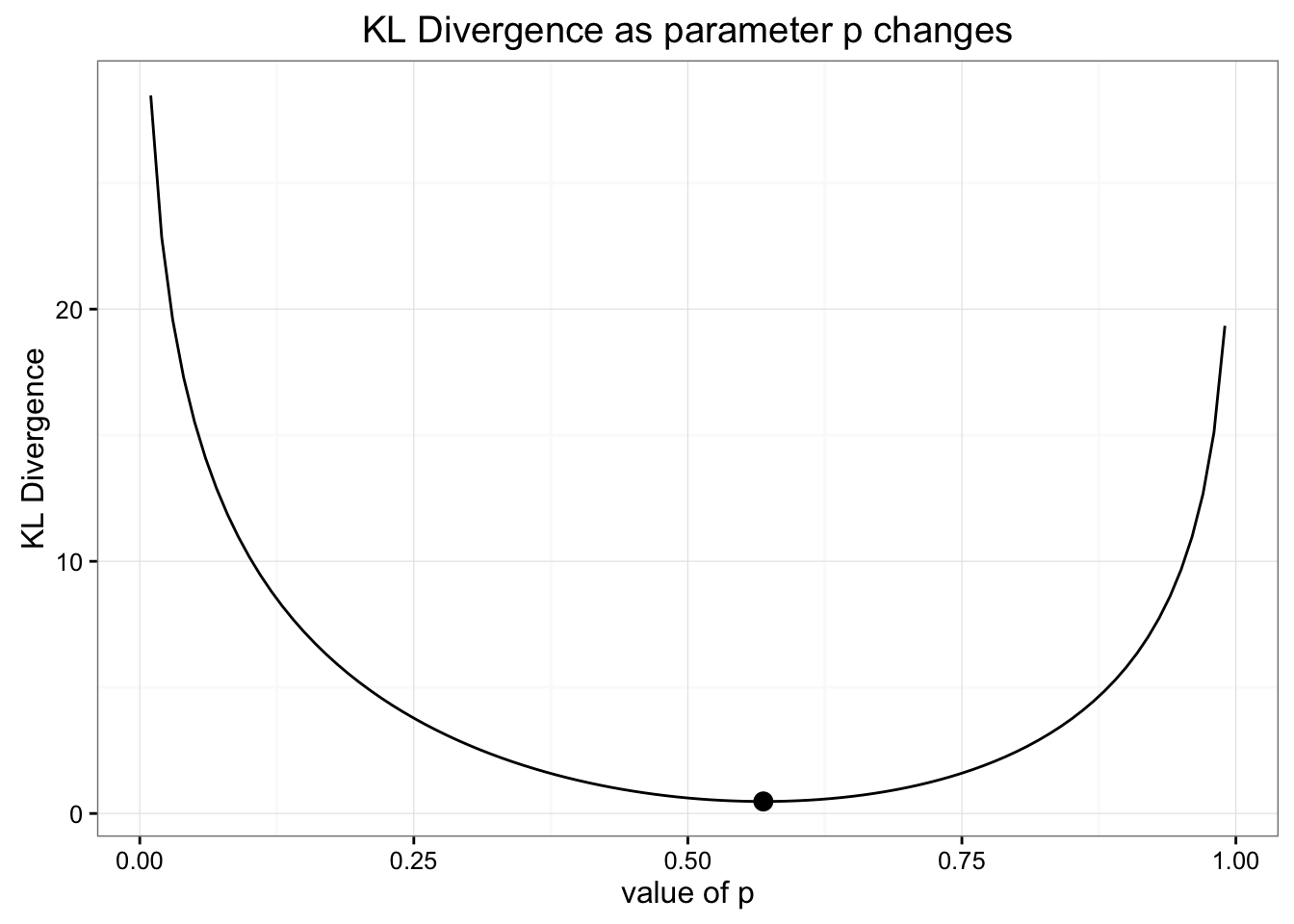
به نظر می رسد ما رویکرد صحیح را برای یافتن بهترین توزیع دوتایی برای مدل سازی داده های خود انتخاب کردیم
همانطور که مشاهده می کنید ، تخمین ما برای توزیع دوتایی (مشخص شده توسط نقطه) بهترین تخمین برای به حداقل رساندن واگرایی KL بود.
فرض کنید ما می خواستیم یک توزیع موقت برای مدل سازی داده های خود ایجاد کنیم. ما داده ها را در دو بخش تقسیم خواهیم کرد. احتمال برای 0-5 دندان و احتمال 6-10 دندان. سپس ما از یک پارامتر واحد استفاده می کنیم تا مشخص کنیم که درصد توزیع احتمال کل در سمت راست توزیع قرار دارد. به عنوان مثال اگر ما 1 را برای پارامتر خود انتخاب کنیم ، 6-10 هر یک احتمال 0. 2 را دارند و همه چیز در گروه 0-5 احتمال 0 را دارد. بنابراین اساساً:
توجه: از آنجا که (log ) برای 0 تعریف نشده است ، تنها زمانی که می توانیم به احتمالات صفر اجازه دهیم این است که (p (x_i) = 0 ) دلالت بر (q (x_i) = 0 ) دارد.
چگونه می توانیم پارامتر بهینه را برای این مدل عجیب و غریب که در کنار هم قرار داده ایم پیدا کنیم؟تنها کاری که باید انجام دهیم این است که واگرایی KL را به همان روشی که قبلاً انجام دادیم به حداقل برسانیم:
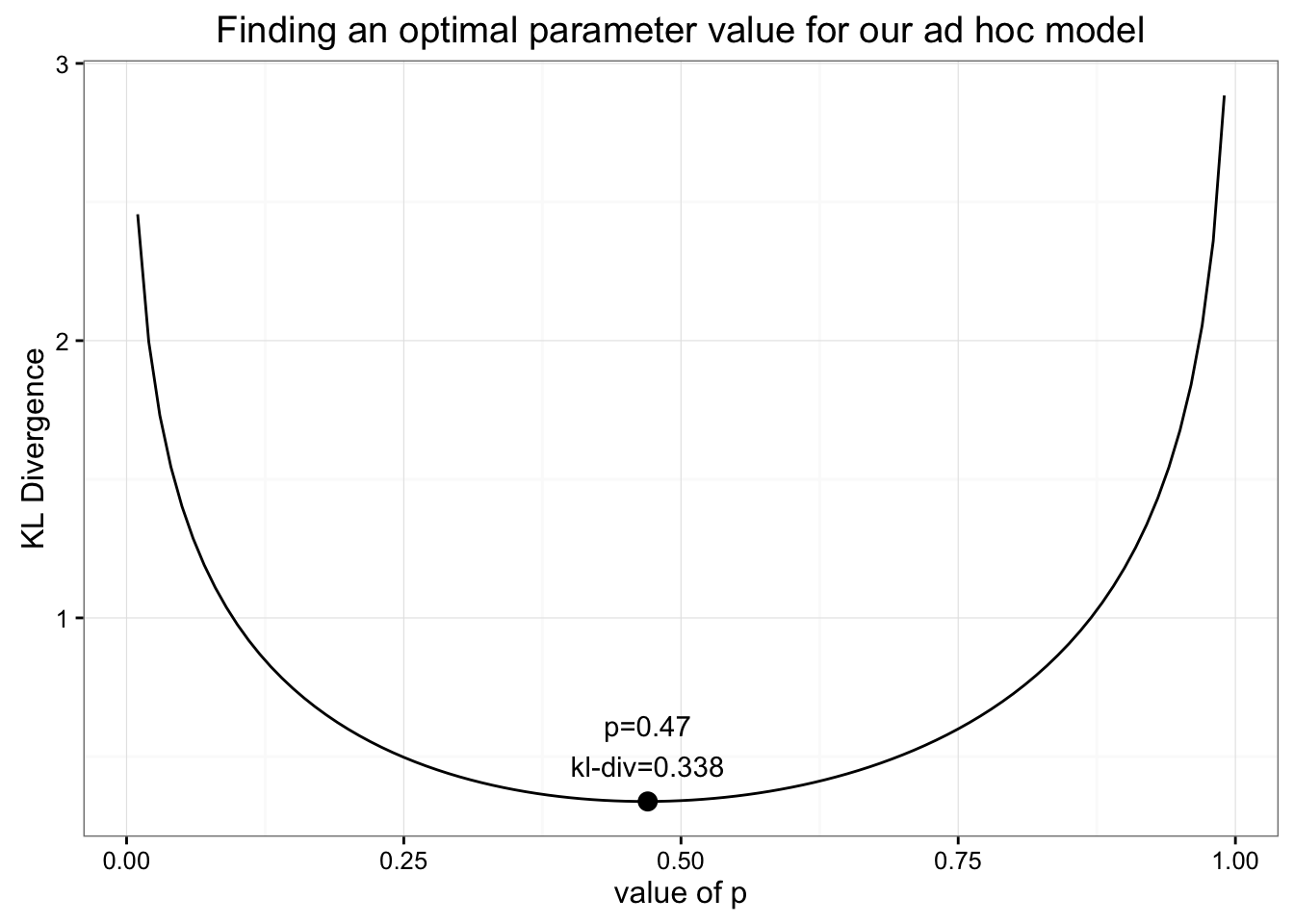
با پیدا کردن حداقل برای واگرایی KL ، زیرا پارامتر خود را تغییر می دهیم می توانیم مقدار بهینه را برای P پیدا کنیم.
ما می دانیم که حداقل مقدار برای واگرایی Kl 0. 338 است که در هنگام (P = 0. 47 ) یافت می شود. این مقدار برای حداقل واگرایی KL باید بسیار آشنا به نظر برسد: تقریباً با ارزش ما از توزیع یکنواخت ما یکسان است! وقتی مقادیر توزیع موقت خود را با مقدار ایده آل برای (P ) ترسیم می کنیم ، می فهمیم که تقریباً یکنواخت است:
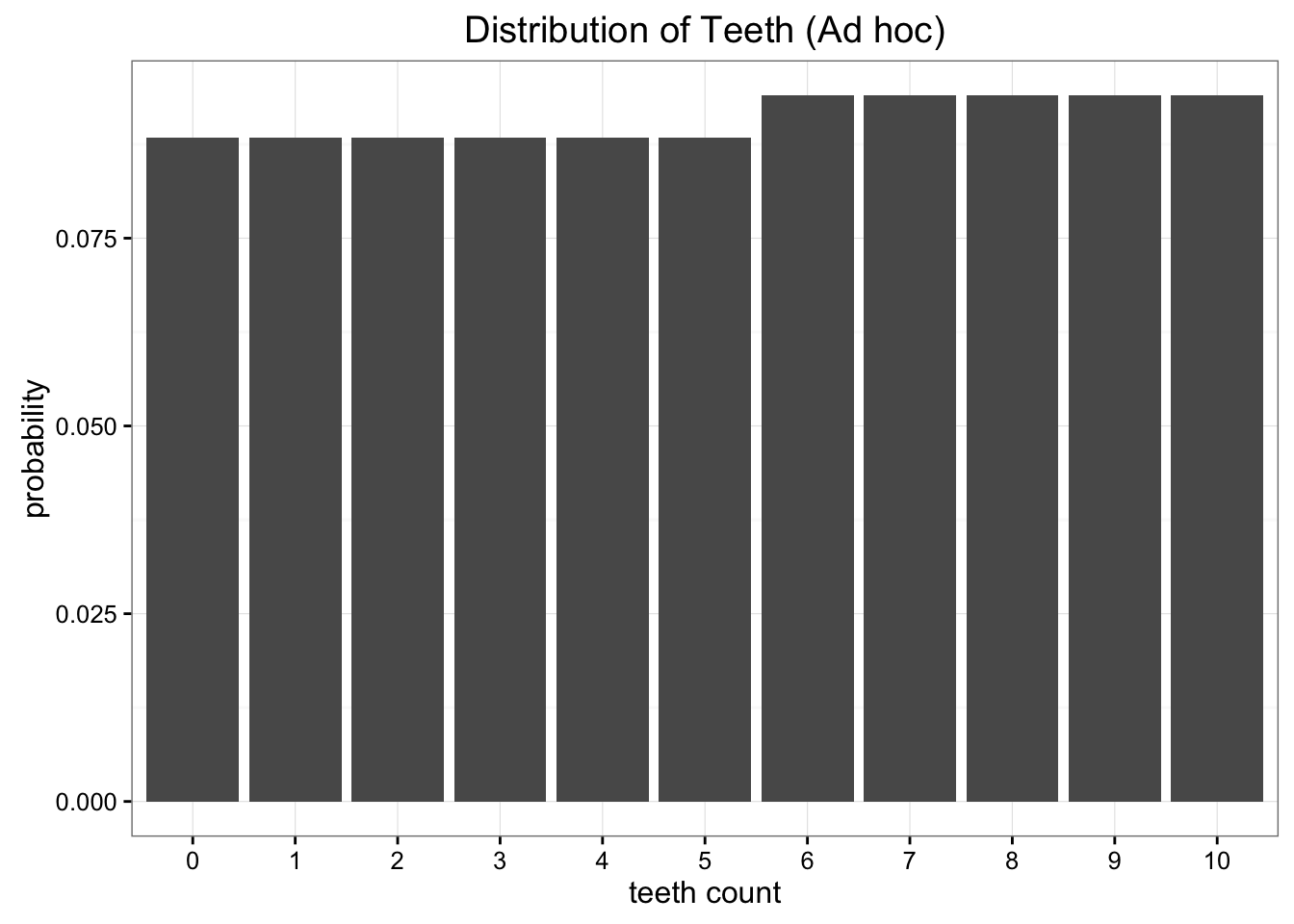
مدل موقت ما بسیار نزدیک به توزیع یکنواخت است
از آنجا که ما با استفاده از توزیع موقت خود ، اطلاعاتی را ذخیره نمی کنیم ، بهتر است با استفاده از یک مدل آشناتر و ساده تر از آن استفاده کنیم.
نکته اصلی در اینجا این است که ما می توانیم از واگرایی KL به عنوان یک تابع هدف استفاده کنیم تا مقدار بهینه را برای هر توزیع تقریبی که می توانیم به دست بیاوریم ، پیدا کنیم. در حالی که این مثال فقط بهینه سازی یک پارامتر واحد است ، ما به راحتی می توانیم تصور کنیم که این رویکرد را به مدلهای ابعادی بالا با پارامترهای زیادی گسترش دهیم.
دستگاههای متغیر و روشهای متغیر بیزی
اگر با شبکه های عصبی آشنا هستید ، ممکن است حدس زده باشید که ما پس از آخرین بخش به آنجا رفتیم. شبکه های عصبی ، به معنای عمومی ، تقریبی عملکرد هستند. این بدان معنی است که می توانید از یک شبکه عصبی برای یادگیری طیف گسترده ای از کارکردهای پیچیده استفاده کنید. نکته اصلی برای گرفتن شبکه های عصبی برای یادگیری استفاده از یک عملکرد عینی است که می تواند به شبکه اطلاع دهد که چقدر خوب است. شما با به حداقل رساندن از دست دادن عملکرد هدف ، شبکه های عصبی را آموزش می دهید.
همانطور که دیدیم ، ما می توانیم از واگرایی KL استفاده کنیم تا میزان ضرر اطلاعات را در هنگام تقریب توزیع به حداقل برسانیم. ترکیب واگرایی KL با شبکه های عصبی به ما این امکان را می دهد تا توزیع تقریبی بسیار پیچیده ای را برای داده های خود بیاموزیم. یک رویکرد متداول در این مورد "AutoEncoder متنوع" نامیده می شود که بهترین روش برای تقریب اطلاعات در یک مجموعه داده را می آموزد. در اینجا یک آموزش عالی وجود دارد که به جزئیات مربوط به خودروهای تغییر دهنده ساختمان می پردازد.
منطقه روشهای متغیر بیزی حتی کلی تر است. در سایر پست ها ، ما دیدیم که چگونه شبیه سازی های مونت کارلو قدرتمند برای حل طیف وسیعی از مشکلات احتمال است. در حالی که شبیه سازی مونت کارلو می تواند به حل بسیاری از انتگرال های غیرقابل تحمل مورد نیاز برای استنباط بیزی کمک کند ، حتی این روش ها می توانند از نظر محاسباتی بسیار گران باشند. روش بیزی متنوع ، از جمله خودروهای متغیر ، از واگرایی KL برای تولید توزیع های تقریبی بهینه استفاده می کند و این امکان را برای استنتاج بسیار کارآمدتر برای انتگرال های بسیار دشوار فراهم می کند. برای کسب اطلاعات بیشتر در مورد استنباط متنوع ، کتابخانه ادوارد را برای پایتون بررسی کنید.
فارکس حرفه ای...
برچسب : نویسنده : مرتضی احباب بازدید : 86
پيوندهای روزانه
لینک دوستان
خبرنامه
